指针扫描
游戏里的”血量地址每次重开都变”——因为它不是固定地址,而是跟着一条指针链被动态 malloc 出来的。指针扫描的工作就是把这条链找出来。
一句话
从目标地址往回搜所有可能指向它的指针链,每一级都记录”从某个静态 base 出发,经过哪些 offset 最后指向目标”。
找到以后,每次重启游戏只要走一遍这条链,就能重新定位到那个动态地址——不管 malloc 把它挪到哪里。
先理解什么是指针链
假设游戏代码里有这样的结构:
struct Player { int hp; ... };
struct PlayerController { Player* player; ... };
struct GameInstance {
PlayerController* pc;
// ...
};
GameInstance* gGameInstance = ...; // 全局变量,每次 boot 都在 libgame.so+0x12345678想看血量,你得:
blood = gGameInstance->pc->player->hp
= *(*(*((char*)0x7faaaaaaaaaa)) + 0x10) + 0x8) + 0x100)从 libgame.so+0x12345678 出发:
- deref 一次(取
gGameInstance指针本身的值)= GameInstance* - +0x10(偏移到
pc字段)然后 deref = PlayerController* - +0x8(偏移到
player字段)然后 deref = Player* - +0x100(偏移到
hp字段)= 血量的最终地址
这样的 (base, off1, off2, off3) 就叫指针链。链条长度一般 3-7 层,热循环里的数据常常藏在很深的地方。
为什么不直接记地址
因为 ASLR。进程每次启动:
- 主程序 binary 基址会变(但相对 offset 不变)
.so库的加载基址也会变- heap 里
malloc出来的对象地址基本随机
Shadow CE 扫出来的血量地址 0x7fa28c1200 只在这次运行有效。重启游戏它肯定变。
但是! libgame.so+0x12345678 这个静态 base不变(相对库)——ASLR 只移动库的基址,库内部 offset 是编译时决定的。
所以指针链的第一个元素是”库名 + 库内 offset”(叫 static base),后面都是固定的 offset。这样的链跨启动稳定。
三个阶段
┌─────────────┐ dump 所有可读可写页 + 筛出可能的指针
│ 1. collect │ 记录每条指针 (addr, value)
└─────┬───────┘
│
▼
┌─────────────┐ 从目标地址反向 BFS
│ 2. BFS │ 每层找"哪些地址存的值恰好指到上一层的某个位置"
└─────┬───────┘
│
▼
┌─────────────┐ 跨重启验证:哪些链每次都能走通?
│ 3. validate│ 留下稳定的,淘汰不稳定的
└─────────────┘阶段 1:Collect
要做什么
把目标进程里所有”看起来像指针”的内存位置记录下来。
怎么做
遍历目标进程的 VMA(通过 /proc/$pid/maps),筛出:
- 可读可写的 anonymous 段(heap / bss / stack)
.data/.bss段(静态 base 的来源)- 排除:ART/dalvik runtime 的内部结构(误判会让链爆炸)、kgsl / mali 的 GPU 共享页(巨大且无意义)
对每一页的每 8 字节对齐的位置,读出那 8 字节的值 v:
if is_pointer_like(v):
pairs.append((addr, v))is_pointer_like 的判据:
v落在某个已知 VMA 里(不是野指针)v不是 tagged ptr 的错误形态(ARM64 MTE / PAC 上半字节要 mask 掉)- 值域合理(不是
0x1234567890abcdef之类明显不对的)
实测数据
SM8750 上某款游戏,一次 collect:
| 指标 | 值 |
|---|---|
| 参与 VMA 总大小 | ~1.2 GB |
| 8 字节指针候选 | ~1500 万条 |
| 过滤后有效指针 | ~600 万条 |
| 耗时 | 82 ms |
| 内存峰值 | ~40 MB |
能这么快是因为 kernel 侧直接 PTE walk 读页,省了 TCP 往返(见 内存扫描)。
内存预算模式
client 提供四档:
| 模式 | buffer 上限 | 大概能扫多少 |
|---|---|---|
| MINI | 5M pairs | 几十 MB 内存 |
| NORMAL | 20M pairs | 300-400 MB |
| LARGE | 40M pairs | ~1.4 GB peak |
| DUMP | 无限 | 写到磁盘 |
NORMAL 是默认,覆盖 99% 的场景。LARGE 在”超大型游戏 / 多进程”情况下才要用,MINI 适合手机内存紧张时。
阶段 2:BFS 反向搜
要做什么
从目标地址 T 出发,反向问:哪些 collect 里的 pair 的”值”指向 T 附近(T - max_offset 到 T)?
找到的那些 pair 的”地址”就是下一层候选。再问:哪些 pair 指向这些候选地址?以此类推。
数据结构
Collect 出来的 pairs: [(addr, value), ...] 按 value 排序(LSD radix sort 8-pass),这样给定一个目标 T 能二分查找所有 value ∈ [T - max_off, T] 的 pair。
核心搜索:
// 查所有值落在 [tgt - max_off, tgt] 的 pair:
for each pair p where pair_upper(p.value) ∈ [tgt - max_off, tgt]:
offset = tgt - p.value
emit_candidate(parent=p.addr, offset=offset)层次
BFS 一层一层走,配一个 depth 限制(默认 5-7 层):
level 0: 目标 T = 血量地址
level 1: 哪些地方的值指向 T-附近 → [A1, A2, A3, ...]
level 2: 哪些地方的值指向 Ai-附近 → [B1, B2, ...]
level 3: ...每一层都会产生爆炸数量的候选(一个常见值可能被几百个地方指着)——这就是为什么要 cap:
| 约束 | 默认 | 意义 |
|---|---|---|
max_depth | 6 | 最多几层 |
max_offset | 0x2000 | 每级偏移不超过 8KB(典型 struct 大小) |
max_per_node | 3 | 每个节点最多保留 3 条入边(避免链式爆炸) |
allow_neg | false | 是否允许负偏移(默认禁,某些 struct 会踩这坑) |
找到”终点” = static base
每一层的父节点可能:
- 落在
.data/.bss段 → 🎯 这就是 static base!链完成 - 落在 heap → 继续往下一层搜
- 深度到顶了还没找到 static base → 丢弃
最终每条完整链形如:
libfoo.so + 0x12345678 → deref + 0x10 → deref + 0x8 → deref + 0x100 → T阶段 3:Validate
为什么要这一步
BFS 找出来的链可能有几十万条。大部分是”数学上成立但实际不稳定”——比如走的是一个临时分配的 buffer,下次启动那里可能是另一回事。
怎么验
关掉游戏、重启、重新连接,让 Shadow CE 沿着每条链走一遍:
验证一条链 = 从 static base 出发 deref + offset deref + offset ... 最后落在有效范围内稳定的链:重启 N 次仍然走得通,且最终值合理(例如血量仍在 0-10000 范围)。
不稳定的链:deref 中途 nullptr、落在随机地方、值明显不对 → 淘汰。
实测
某款 FPS 游戏,对弹药地址扫出 25088 条候选,重启验证 1 次后剩 11 条,3 次重启后稳定剩 5 条。最终采用其中最短的:
libgame.so + 0x5A8F40 → deref + 0x30 → deref + 0x120 → deref + 0x1440 = ammo跨 20 次重启稳定有效。
典型实战:FPS2 的弹药链
一次真实案例。
目标:找 FPS2 游戏的子弹数地址,希望在跨重启后还能用。
步骤 1 — 扫血量(或类似稳定值)
先用内存扫描锁定一个数值变量(这里是子弹数 30)。
步骤 2 — 右键 → “Pointer scan for this address”
PtrScan Settings dialog 打开:
target address: 0x7faaaaaaaaaa
max depth: 6
max offset: 0x2000
filter modules: [✓] .data/.bss only (static base)
memory budget: NORMAL (20M pairs)步骤 3 — 按下 Start
collect(82ms)→ BFS(~3 秒)→ 结果窗口显示 25088 条候选。
步骤 4 — 复制一条链到 address list 验证
选一条链,菜单 → “Copy to address list”,观察值。打子弹 → 值递减 → ✅。
步骤 5 — 重启游戏 → 右键链 → “Rescan”
rescan 会重新连接,沿每条链 walk 一遍,淘汰 null-deref / 无效范围的。25088 → 11。
步骤 6 — 再重启 2-3 次
11 → 5。稳定了,可以信。
步骤 7 — 保存
右键 → “Save chain to .ptr file”。下次开游戏可以直接 load + walk,不用重扫。
最终链(FPS2 弹药)
GEngine @ libgame.so + 0x5A8F40
→ deref + 0x30 (GameViewportClient)
→ deref + 0x8 (GameInstance)
→ deref + 0x48 (LocalPlayer)
→ deref + 0x10 (PlayerController)
→ deref + 0x120 (Character)
→ deref + 0x1440 (CurrentAmmo)7 层,长但稳定。
参数调优手册
max_depth
- 越大:能找到更深的链
- 越大:候选爆炸、时间爆炸
实战默认 6。UE4 游戏常见 5-7 层,Unity 3-5 层。
max_offset
- 越大:能捕获稀疏结构体里的字段(如巨大数组)
- 越大:同一层出现大量”凑巧值”的误判
实战默认 0x2000 (8KB)。如果目标变量明显在大 struct 里(例如 Character 有好几千字节),可以加到 0x8000。
max_per_node
- 每个节点保留几条入边
- 默认 3 足够;调到 10 会让候选数 × 3
allow_neg
- 负偏移:有时候 C 代码里会
parent_of(this)这样引用 - 默认关。打开后链数翻倍,但能找到一些罕见结构
内存预算选哪个
| 游戏规模 | 建议 |
|---|---|
| 手游 Unity (< 500MB 进程) | MINI 或 NORMAL |
| 3A UE4 (~1-2GB) | NORMAL |
| 大型 UE5 / 多进程 | LARGE |
| 扫完写磁盘分析 | DUMP |
那些踩过的坑
| 坑 | 现象 | 教训 |
|---|---|---|
| UE4 反向扫极难 | UE4 类继承深、vtable 多、一个对象被多处引用 → 链爆炸 | 用 SDK dump 先定位字段名,再扫 |
| 代码段被误认指针 | ASLR 下 .text 里常有 4 字节对齐的”像指针”的值 | collect 阶段把 EXEC 段排除 |
.bss 不是 file-backed | Linux .bss 是 anonymous 段,不带文件名 | 用”anon after rw file mapping”启发式识别 |
| ART/dalvik 引用 | Android runtime 内部大量”Class*→Method*→…”引用 → 误判成游戏结构 | 显式过滤 ART/ dalvik / libc 相关的 VMA |
addr += offset 方向错了 | 一开始代码把 p.value - offset 当父 → BFS 整个反向了 | 严格区分 parent 指向 child 和 child 被 parent 指 |
untagged_addr 硬编码 | ARM64 MTE / PAC 上半字节不是零 → 匹配失败 | collect 时统一 v & 0xFFFFFFFFFFFF |
| QTimer.singleShot 子线程失效 | Worker 线程里 QTimer.singleShot(0, slot) 不会触发 | 用 pyqtSignal emit 到主线程 |
| pairs_tmp 320MB OOM | 临时 buffer 用 Python list 保存,内存爆了 | 改用 array.array('Q') 或 numpy.uint64 |
| VMA iterator use-after-free | 遍历 VMA 时进程 mmap/munmap,链表变动 | 加 mmap_read_lock |
UI —— 两个对话框
PtrScanSettingsDialog
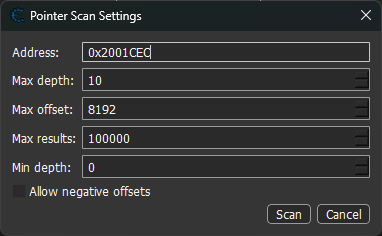
选 target、模式、depth、offset、filter。按 Start 之后对话框最小化、开始 collect。
┌─ Pointer Scan Settings ────────────────┐
│ Target address: [0x7faaaaaaaaaa_____] │
│ Memory budget: ( )MINI (●)NORMAL │
│ ( )LARGE ( )DUMP │
│ Max depth: [6] Max offset: [2000] │
│ Max per node: [3] □ allow negative│
│ │
│ Filter: │
│ [✓] .data / .bss only (static base) │
│ [✓] exclude ART/dalvik │
│ [ ] include executable pages │
│ │
│ [ Cancel ] [ Start ] │
└────────────────────────────────────────┘PtrScanResultsWindow
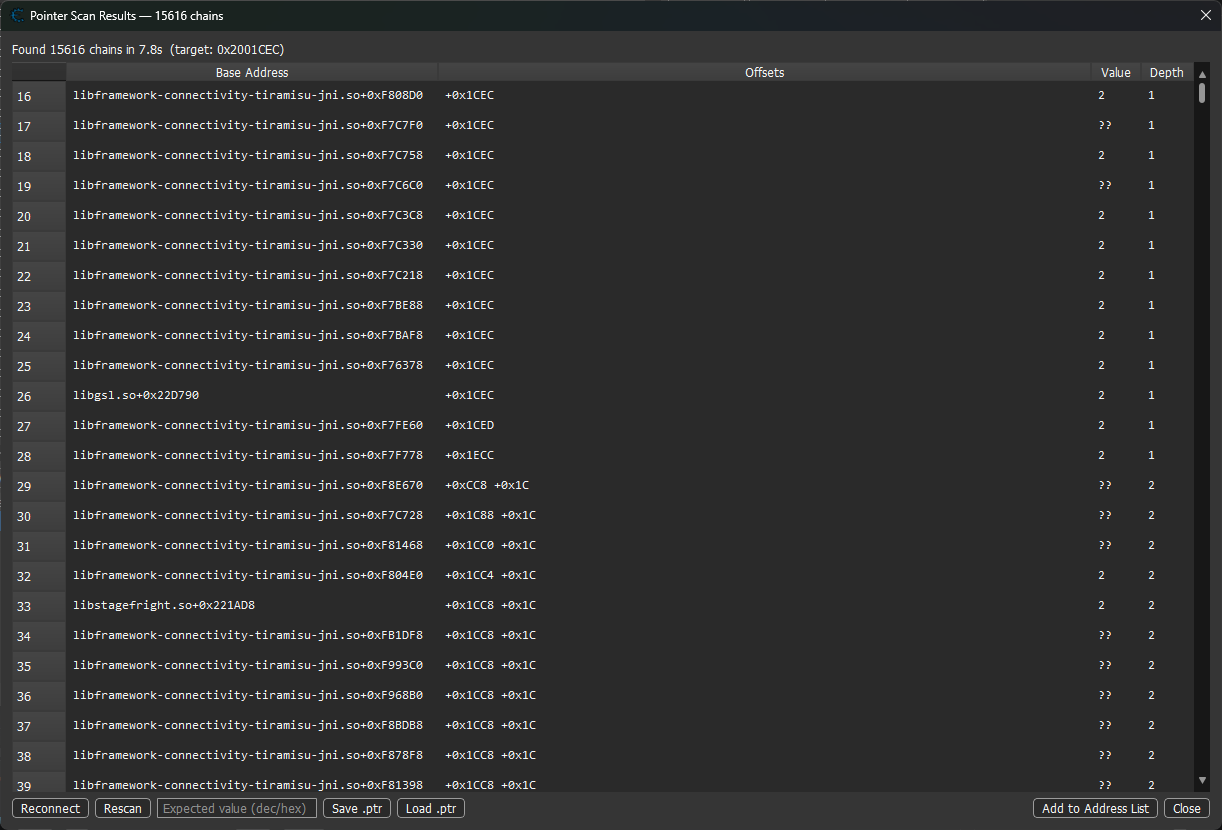
顶部状态条写 Found 15616 chains in 7.8s (target: 0x2001CEC);每行是一条 Base Address | Offsets | Value | Depth。底栏 Reconnect / Rescan / Save .ptr / Load .ptr / Add to Address List / Close —— Rescan 会重连目标进程重走每条链,淘汰死链。
扫完弹出。每一行是一条完整链:
┌─ Pointer Scan Results — 25088 chains ──────────────┐
│ [filter: ____] [save] [load] [rescan] [delete] │
├────────────────────────────────────────────────────┤
│ # Chain Live val │
│ 1 libgame+0x5A8F40 → +0x30 → +0x120 → ... = 30 │
│ 2 libgame+0x5B1000 → +0x8 → +0x100 ... = 30 │
│ ... │
└────────────────────────────────────────────────────┘- 每行末尾的 Live val 是沿链 walk 出来的当前值——可以实时盯着,确认没跑偏
- Viewport 只渲染可见行(virtual table),20000 条链也不卡
- 菜单 →
Save chain as .ptr/Load .ptr file/ 左键双击打开地址 / 右键加入 address list
Rescan 按钮做的事:重连、逐链 walk、淘汰 null-deref 的。
协议速查
| CMD | 作用 | Payload |
|---|---|---|
0xD6 PTRSCAN_COLLECT | 启动 collect,扫 VMA 收集 pairs | {target, mode, filter_flags} |
0xD7 PTRSCAN_BFS | 用已 collect 的 pairs 做 BFS | {max_depth, max_offset, ...} |
0xD8 PTRSCAN_CHAIN_WALK | 沿一条链走,返回最终地址 + 中间地址 | {base, offsets[]} |
Results 文件格式是简单的 JSON + binary offsets array。
内核侧一眼(仅作了解)
server/kern_ptrscan.h 里:
- pairs storage:
vmalloc一大块,40M × 16B = 640 MB 预算 - 排序:LSD radix sort 8-pass(U64 按字节拆 8 遍 counting sort)——比
qsort快几倍 - BFS 状态机:每轮遍历当前层节点,二分查
pair_upper,emit 下一层节点 - visited 表:hash set(linear probe),避免同一节点被反复扩展
- 并发性:整个扫描是 blocking 的,暂不支持中途取消(改进中)
更深的实现细节不在本页——有兴趣看源码直接读。
和其它功能的配合
- 内存扫描 帮你找到”这次运行里的绝对地址” → 扔给指针扫描作为 target
- 反汇编 / Hexview 帮你在 disasm 里看这些 offset 对应的是 struct 哪个字段
- 用户态硬件断点 装在指针链终点上,可以看”谁每一帧在改这个字段”
什么时候别用
- 找一次性 buffer:一个
new byte[16]这种分配出去只用几秒的东西,链根本不稳定 - 需要实时追踪每帧变化:指针扫描是离线过程(~秒级);实时追踪请用 HWBP
- 超大游戏 >4GB 进程:目前 buffer cap 40M pair 不够;需要上 DUMP 模式 + 自己写分析
深度资料
client/ptrscan_dialog.py(716 行)— Settings + Results + Workerserver/kern_ptrscan.h(584 行)— collect / BFS / chain walk 内核实现server/usr_server.c— CMD handler(grep0xD6 / 0xD7 / 0xD8)server/shadow_ce.h— 协议结构体
历史笔记(dev-history 里)包含 v3 → v4 算法演进、BFS vs DFS 选型理由、FPS2 实战完整过程——不在公开文档里,但源码注释保留了关键结论。