内存扫描
Shadow CE 最核心的能力:在目标 Android 进程上做 Cheat-Engine 风格的内存搜索 —— first scan / next scan / 锁值 / 跨视图跳转。
整条链路的设计目标只有一个:零 ptrace、零 /proc/pid/mem、零 process_vm_readv。所有进程内存访问都走 shadow_ce.ko 的 page-table walk,不触碰游戏反作弊最熟悉的那些系统接口。
UI 层(扫描面板控件、拖拽、address list、hex/disasm 跳转的 UI 侧)见 UI 设计;这里专注扫描逻辑 + 协议 + 内核页读机制。
实拍
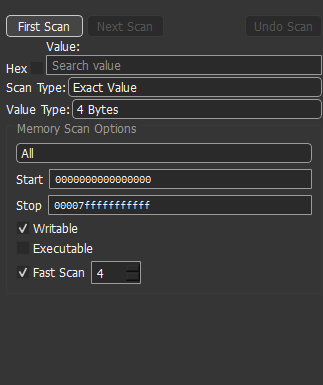
右侧扫描面板:四段式 —— First/Next/Undo 三个按钮、Value 输入 + Hex 开关、Scan Type / Value Type 两个下拉、底部 Memory Scan Options(Region / Start-Stop / Writable / Executable / Fast Scan 步长)。
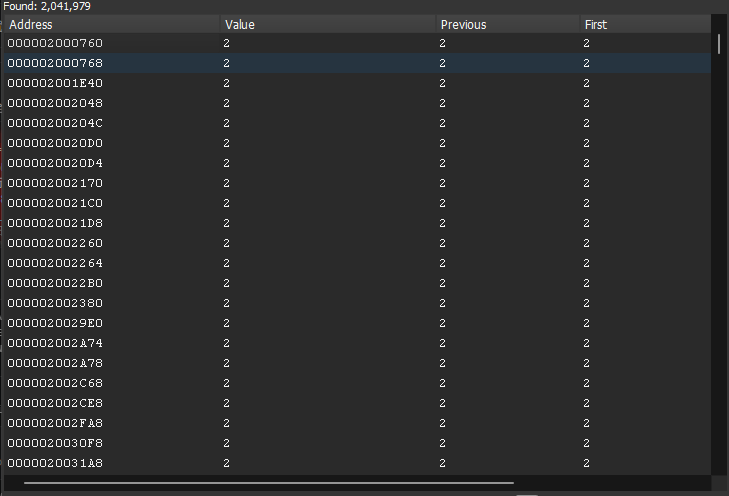
结果表:等宽 hex 地址 + 当前值 + Previous + First 四列,顶栏 Found: 2,041,979 实时跟踪命中数(这里是首次扫 Exact Value = 2 的瞬间,>200 万个候选)。Next Scan 一次过滤后数字会断崖式掉。
1. 扫描管线总览
1.1 端到端数据流
┌──────────────────────────────────────────────────────────────────────┐
│ PyQt Client (Python) │
│ ┌────────────────┐ ┌────────────┐ ┌──────────────────┐ │
│ │ Scan UI panel │───▶│ Scanner │───▶│ CEClient (TCP) │ │
│ │ main_window.py │ │ scanner.py │ │ ce_client.py │ │
│ └────────────────┘ └────────────┘ └──────────────────┘ │
└──────────────────────────────────────────┬───────────────────────────┘
│ TCP 16900 (default 52736)
▼
┌──────────────────────────────────────────────────────────────────────┐
│ Android userspace (ce_server, ARM64 static) │
│ ┌──────────────────┐ ┌────────────────────┐ │
│ │ TCP dispatcher │───▶│ ioctl(/dev/cxXXXXXX│ │
│ │ usr_server.c │ │ SHADOW_CE_SCAN) │ │
│ └──────────────────┘ └────────────────────┘ │
└──────────────────────────────────────────┬───────────────────────────┘
│ ioctl
▼
┌──────────────────────────────────────────────────────────────────────┐
│ Android kernel (shadow_ce.ko) │
│ kern_shadow_ce.c ──▶ kern_mem.h: mem_scan / mem_rescan / mem_rw │
│ ├─ pgd → p4d → pud → pmd → pte walk │
│ ├─ huge page (1G/2M) 处理 │
│ ├─ vm_normal_page 安全检查 │
│ └─ kmap_local_page + memcpy │
└──────────────────────────────────────────────────────────────────────┘1.2 一次 first-scan 的时序图
1.3 为什么不走 ptrace / /proc/pid/mem
| 接口 | 反检测风险 | 备注 |
|---|---|---|
ptrace(PTRACE_ATTACH) | 极高 | 目标进程 task->ptrace != 0,/proc/self/status: TracerPid: 非零 |
/proc/pid/mem | 高 | TerSafe 会扫 fd 打开路径,历史上出现过封号事故 |
process_vm_readv(2) | 中 | 需要 PTRACE_MODE_ATTACH_REALCREDS 检查,syscall trace 能看到 |
| ioctl + PTE walk (ours) | 极低 | 来自一个名字随机的 /dev/cxXXXXXX 字符设备,无任何 trace 状态 |
设备名本身也是伪装:kern_shadow_ce.c:276-280 里 "cx" + 6 随机字母,ce_server 启动时扫 /dev/cx* 自动发现(usr_server.c:1176-1196)。
2. Value types
2.1 客户端定义
scanner.py:8-11:
VALUE_TYPES = {
"Byte": (1, "B"), "2 Bytes": (2, "<H"), "4 Bytes": (4, "<I"),
"8 Bytes": (8, "<Q"), "Float": (4, "<f"), "Double": (8, "<d"),
}元组 (size, struct_fmt):
| UI 名 | size | struct fmt | 端序 | 有符号? | 常用场景 |
|---|---|---|---|---|---|
| Byte | 1 | B | n/a | 无符号 | HP/ammo 低字节、flag |
| 2 Bytes | 2 | <H | LE | 无符号 | 小型计数、坐标像素 |
| 4 Bytes | 4 | <I | LE | 无符号 | UE4 int32 字段,最常用 |
| 8 Bytes | 8 | <Q | LE | 无符号 | 指针、int64、时间戳 |
| Float | 4 | <f | LE IEEE-754 | 带符号 | 坐标、速度、生命值小数 |
| Double | 8 | <d | LE IEEE-754 | 带符号 | 少见,UE4 更多用 float |
2.2 类型转换
scanner.py:61-66 —— 用户输入字符串 → 指定字节宽度的 bytes:
def parse_val(self, text, vtype, is_hex):
sz, fmt = VALUE_TYPES[vtype]
if vtype in ("Float", "Double"):
return struct.pack(fmt, float(text))
return struct.pack(fmt, int(text, 16 if is_hex else 10))is_hex 开关来自 UI 的 Hex 复选框。
2.3 Signed vs unsigned 的一个坑
客户端 VALUE_TYPES 只声明了无符号格式。当用户勾选 show_signed(AddrEntry.show_signed,在 address list 里生效),展示时额外做一次”按 bit 反解”。但扫描协议往下走全是无符号 uint64 零扩展(见 § 2.4),对于 int32 存着 -1(0xFFFFFFFF)这种情况,Increased/Decreased 无符号比较会得到直觉相反的结果。实战里扫负数血量基本没人这么干,所以没改。
2.4 Endianness
全 little-endian。ARM64 Linux 用户态 LE,协议层直接按 < 格式 pack,内核侧 mem_val_match()(kern_mem.h:438)用 memcpy(&val, buf, sz) 把页上 sz 字节当 CPU 字节序读进 unsigned long,天然和 LE 对齐。
2.5 Float 的 ULP 容差(未走通)
kern_mem.h:53-55,418-436 里预留了 float/double 的 ULP 近似匹配:
#define MEM_FLOAT_ULP_TOL 256
#define MEM_DOUBLE_ULP_TOL 512
static inline int mem_float_near(uint32_t a, uint32_t b) { ... }
static inline int mem_double_near(uint64_t a, uint64_t b) { ... }但 mem_val_match()(kern_mem.h:438-453)目前只按整数比较,float/double 的近似匹配没接进去。SCAN_EXACT 对 float 实际上在比 IEEE-754 bit 精确相等。工程上要扫”约等于 100.0 的 float”只能靠 Between 缩范围。
3. First scan
3.1 入口
UI 点 First Scan → main_window.py:980 _on_scan → _do_first_scan(main_window.py:991)。
关键步骤:
- 取当前
vtype+ scan type 下拉选项。 - 映射 scan type 文字到协议常量
scan_type_map = {"Exact Value": 0, "Bigger than": 1, "Smaller than": 2, "Between": 3}(main_window.py:1004)。 - float / double →
struct.pack → unpack转 IEEE-754 uint bit。 - 读扫描范围
inp_start/inp_stop(默认 0 到 0x7fffffffffff,即 47-bit 用户地址空间 top)。 - 读 prot filter:
chk_writable→ bit0,chk_exec→ bit1(详见 § 3.3)。 - 在工作线程里调
self.client.scan(...)。
3.2 客户端协议封包
ce_client.py:145-166 scan:
self._send(bytes([0xC8])) # CMD_SCAN
self._send(struct.pack("<IQQIIIIqqI",
handle, start, stop,
val_size, scan_type, align, prot_filter,
value, value2, max_results))
# 响应:uint32 count + count * uint64 addr字段语义:
| 偏移 | 类型 | 字段 | 说明 |
|---|---|---|---|
| 0 | u32 | handle | 打开的 pid(也就是 opened_pid) |
| 4 | u64 | start | 起始地址(VA) |
| 12 | u64 | stop | 结束地址(VA,exclusive) |
| 20 | u32 | val_size | 1/2/4/8 |
| 24 | u32 | scan_type | SCAN_EXACT/BIGGER/SMALLER/BETWEEN |
| 28 | u32 | align | 步进(扫描粒度) |
| 32 | u32 | prot_filter | bit0=writable, bit1=exec |
| 36 | i64 | val1 | 搜索值(u64 零扩展,float bit 复用) |
| 44 | i64 | val2 | Between 的上限 |
| 52 | u32 | max_results | 0 → 默认 100000;上限 10000000 |
协议常量和 shadow_ce.h 里对齐:
#define SCAN_EXACT 0
#define SCAN_BIGGER 1
#define SCAN_SMALLER 2
#define SCAN_BETWEEN 3CMD_SCAN = 0xC8 定义在 usr_server.c:43。
3.3 Prot filter 的小语义
prot_filter == 0→ 扫所有可读 VMA(基础过滤:vma->vm_flags & VM_READ)prot_filter & 1→ 只扫可写(VM_WRITE)prot_filter & 2→ 只扫可执行(VM_EXEC)3= writable && exec(一般无人勾,R+W+X 的页很少)
Unconditionally 跳过 VM_IO | VM_PFNMAP(kern_mem.h:509-510),这是 device-mapped 物理区,既读不出也可能 panic。
实战经验:扫游戏状态(HP、ammo、坐标)建议勾 Writable —— 常量字符串、只读 .rodata 没必要扫;能减少 90% 的假阳。UE4 游戏 heap 基本都在 writable 匿名 VMA 里。
3.4 “Unknown initial value” 语义
UI 下拉选项 "Unknown initial value"(scanner.py:13)没有对应的协议 scan_type。当前实现里 Unknown scan 走的是”val1_text 为空就提前 return”(main_window.py:996)的路径,真正的 unknown initial value 工作流还未完整落地,属于 placeholder 语义。
3.5 Scan 结果回传
客户端收到 count * uint64 的地址列表之后,在 main_window.py:1038-1054 里把每个地址包装成 ScanResult:
@dataclass
class ScanResult:
address: int
value: bytes # 当前值(用 val1 初始化,方便 UI 立刻渲染)
previous: bytes = b"" # 上一轮 scan 的值(next scan 时会更新)
first: bytes = b"" # 第一次 scan 时看到的值(列 "First")注意 value/previous/first 初始都设成 val1 的 pack,因为协议里 first scan 不回传每个地址的实际值。实际的”real value” 要靠后面的 _refresh_result_values 批量补读 —— 这条路径走 CMD_READ_BATCH (0xCB),main_window.py:1262-1266。
3.6 内核侧 first-scan 算法
完整逻辑在 kern_mem.h:457-581 mem_scan。要点:
A. 分块锁策略(MEM_SCAN_CHUNK_PAGES = 1024,kern_mem.h:48)
- 每持
mmap_read_lock(mm)扫 1024 个页(≈ 4MB 数据)就释放一次,cond_resched(),下一轮再拿锁。 - 防止长时间占锁卡住目标进程的 fork / mmap / brk。
- 之前一把锁扫到底,游戏会卡帧 1-2 秒,反作弊能察觉”MMU 卡顿”。
B. VMA 迭代(kern_mem.h:494-510)
VMA_ITERATOR(vmi, mm, cursor);
for_each_vma(vmi, vma) {
if (vma->vm_start >= req->stop) break;
if (!(vma->vm_flags & VM_READ)) continue;
if ((req->prot_filter & 1) && !(vma->vm_flags & VM_WRITE)) continue;
if ((req->prot_filter & 2) && !(vma->vm_flags & VM_EXEC)) continue;
if (vma->vm_flags & (VM_IO | VM_PFNMAP)) continue;
...
}cursor 是跨 chunk 的进度指针。
C. 逐页 walk + kmap 扫描
pr = mem_walk_pte(mm, vma, addr); // ← § 5 详述
get_page(pr.page); if (pr.ptep) pte_unmap(pr.ptep);
kaddr = kmap_local_page(pr.page);
for (; off + req->val_size <= end_off; off += req->align) {
if (mem_val_match(kaddr + off, req->val1, req->val2, req->val_size,
req->scan_type))
results[found++] = (addr & PAGE_MASK) + off;
}
kunmap_local(kaddr);
put_page(pr.page);mem_val_match(kern_mem.h:438-453)就是标准的 cmp:
unsigned long val = 0;
memcpy(&val, buf, sz);
switch (type) {
case SCAN_EXACT: return val == v1;
case SCAN_BIGGER: return val > v1;
case SCAN_SMALLER: return val < v1;
case SCAN_BETWEEN: return val >= v1 && val <= v2;
}D. 结果缓冲
results = vmalloc(max_results * sizeof(unsigned long))(kern_mem.h:476)—— 最大 10M 地址 ≈ 80MB 连续分配。kmalloc 80MB 肯定失败,用 vmalloc 走 per-page + vmap。扫描完一次性 copy_to_user。
E. 中断响应
每页调 signal_pending(current)(kern_mem.h:521-522)检查,用户进程(= ce_server 的 ioctl 线程)被 SIGTERM 时能及时 goto out。早期版本没这个检查,kill server 之后 ioctl 线程卡 D-state 几分钟。
F. Huge page 支持
mem_walk_pte 会在 PUD sect(1GB)或 PMD sect(2MB THP)成立时直接把整个 huge page 的 struct page 返回。scan 里用的还是 PAGE_SIZE 逐步切分,因为 kmap 也只拿了 4KB —— 但 pr.page 指向的是 huge page head,配合 (addr & ~PAGE_MASK) 偏移还是能对。Huge page 上的扫描能跑但没特化,参考 § 5.6 的已知 limitation。
4. Next scan
4.1 协议与语义
客户端 ce_client.py:168-203 rescan → CMD_RESCAN = 0xC9。
Wire format(usr_server.c:708-784):
req: [u32 pid][u32 val_size][u32 scan_type]
[u64 val1][u64 val2]
[u32 in_count][u32 has_prev]
+ in_count × u64 addr
+ (has_prev ? in_count × u64 prev : 0)
resp: [u32 count][count × (u64 addr, u64 cur)]关键设计:cur 由内核直接回填,next scan 响应本身就自带每个地址的当前值,客户端不用再发 READ_BATCH 补读 —— 一轮 TCP 直接拿到 “过滤后结果 + 新值”。
4.2 scan_type 扩展表
| scan_type | const | UI 文字 | 语义 | 需要 prev? |
|---|---|---|---|---|
| 0 | SCAN_EXACT | Exact Value | cur == val1 | 否 |
| 1 | SCAN_BIGGER | Bigger than | cur > val1 | 否 |
| 2 | SCAN_SMALLER | Smaller than | cur < val1 | 否 |
| 3 | SCAN_BETWEEN | Between | val1 ≤ cur ≤ val2 | 否 |
| 4 | SCAN_CHANGED | Changed | cur != prev | 是 |
| 5 | SCAN_UNCHANGED | Unchanged | cur == prev | 是 |
| 6 | SCAN_INCREASED | Increased | cur > prev | 是 |
| 7 | SCAN_DECREASED | Decreased | cur < prev | 是 |
相对比较类(4-7)叫 “relative ops”,client 端通过集合判断:
main_window.py:1081:
is_relative = scan_type in (4, 5, 6, 7)scanner.py:14-16:
SCAN_NEXT = ["Exact Value", "Bigger than", "Smaller than", "Between",
"Increased", "Decreased", "Changed", "Unchanged",
"Increased by", "Decreased by"]注意 UI 列出的 Increased by / Decreased by 目前没有协议编号,属于未实装选项。
4.3 _RESCAN_NO_INPUT 与 value-input 禁用
main_window.py:27:
_RESCAN_NO_INPUT = {"Increased", "Decreased", "Changed", "Unchanged",
"Unknown initial value"}当用户选这五项时,_on_scan_type_changed(main_window.py:968-978)把 value 输入框 disable 掉 —— 相对比较不需要用户输入值,kernel 会用客户端发过来的 prev 来判断。
4.4 客户端 prev_vals 打包
main_window.py:1107-1112:
prev_vals = None
if is_relative:
prev_vals = [
int.from_bytes((r.value or b"").ljust(8, b"\x00")[:8], "little")
for r in self.scanner.results
]每个 ScanResult.value(val_size 字节)zero-extend 到 8 字节再按 LE 拼成 u64 —— 内核侧用 unsigned long 接收(kern_mem.h:647)。
4.5 内核侧 mem_rescan
kern_mem.h:585-712:
need_prev = (req->scan_type == SCAN_CHANGED ||
req->scan_type == SCAN_UNCHANGED ||
req->scan_type == SCAN_INCREASED ||
req->scan_type == SCAN_DECREASED);
if (need_prev && !req->in_prevs)
return -EINVAL;然后分 512 地址一批(MEM_RESCAN_CHUNK = 512)拿锁扫,每个地址 vma_lookup → mem_walk_pte → kmap → memcpy(&cur_val),根据 scan_type 做 8 路 switch,命中就 out_matches[found].addr = addr; out_matches[found].cur = cur_val;。
核心差别与 first-scan:
- 输入是离散地址集,而不是连续范围。对每个地址做一次 VMA lookup + PTE walk —— 一次 rescan 1M 地址 ≈ 1M 次 walk,但由于 mmap lock 粒度 512 地址 / 批,依然很快。
- VMA 判
VM_IO|VM_PFNMAP就跳,不是copy_to_user零填充(kern_mem.h:658)。 - 出参
ce_rescan_match[]成对返回(addr, cur):
struct ce_rescan_match {
unsigned long addr;
unsigned long cur;
};4.6 结果合并与 first / previous / value
main_window.py:1124-1136:
for addr, cur_u64 in matches:
cur_bytes = (cur_u64 & mask).to_bytes(val_size, "little")
old = old_map.get(addr)
prev_bytes = old.value if old else cur_bytes
first_bytes = (old.first if (old and old.first) else cur_bytes)
new_results.append(ScanResult(
address=addr, value=cur_bytes,
previous=prev_bytes, first=first_bytes))first:永远从旧 result 里继承,不跟着 next-scan 变 —— 这就是 CE 的 “First” 列语义:永远显示第一次 scan 时的值。previous:上一轮的value,下一次 relative rescan 的对照。value:本次 rescan 响应里带回来的cur。
4.7 Undo
scanner.py:83-86:
def undo_scan(self):
if self.undo_results:
self.results = self.undo_results
self.undo_results = []main_window.py:1101 每次 next-scan 前把当前 results 拷进 undo_results。只保留一步 undo,不是完整栈 —— 和 CE 的行为对齐。
5. 内核侧页读取 (kern_mem.h)
整个 ko 里最关键的原语是 mem_walk_pte(kern_mem.h:69-139)—— 从 mm->pgd 走 ARM64 4 级页表到 struct page *。
5.1 ARM64 4 级页表回顾
默认 4KB 页、48-bit VA 下:
VA[47:39] → PGD index (512 entries)
VA[38:30] → PUD index (512) ← PUD sect = 1 GB huge
VA[29:21] → PMD index (512) ← PMD sect = 2 MB huge (THP)
VA[20:12] → PTE index (512)
VA[11:0] → page offsetp4d 在 ARM64 上是一层 NO-OP(5-level paging 保留),p4d_offset(pgd, addr) 直接返回 pgd。代码里仍然走 p4d 是为了跨架构兼容。
5.2 走表的关键片段
pgd = pgd_offset(mm, addr);
if (pgd_none(READ_ONCE(*pgd))) return res;
p4d = p4d_offset(pgd, addr);
if (p4d_none(READ_ONCE(*p4d))) return res;
pud = pud_offset(p4d, addr);
if (pud_none(READ_ONCE(*pud))) return res;
/* 1GB huge page? */
if (pud_sect(READ_ONCE(*pud))) {
unsigned long pfn = pud_pfn(READ_ONCE(*pud));
pfn += (addr & ~PUD_MASK) >> PAGE_SHIFT;
if (!pfn_valid(pfn)) return res;
res.page = pfn_to_page(pfn);
res.size = PUD_SIZE;
return res;
}
pmd = pmd_offset(pud, addr);
pmdval = READ_ONCE(*pmd);
if (pmd_none(pmdval)) return res;
/* 2MB huge page (THP)? */
if (pmd_sect(pmdval)) { ... res.size = PMD_SIZE; return res; }
res.ptep = pte_offset_map(pmd, addr);
if (!res.ptep) return res;
pteval = READ_ONCE(*res.ptep);
if (pte_none(pteval) || !pte_present(pteval)) { ... return res; }
if (pte_special(pteval) || pte_devmap(pteval)) { ... return res; }
res.page = vm_normal_page(vma, addr, pteval);
if (!res.page) { ... return res; }
res.size = PAGE_SIZE;5.3 安全检查的每一条都有血的教训
| 检查 | 绕过后果 |
|---|---|
pte_present | 读 swap 或 migration 条目 → oops |
pte_special(AF/PFN-only 映射) | struct page 不存在 → null deref |
pte_devmap | DAX 设备内存,生命周期特殊 |
vm_normal_page | 正确处理 copy-on-write / huge / zero-page 边界 |
pfn_valid (huge 路径) | pfn 越界 → pfn_to_page 返回野指针 |
VM_IO | VM_PFNMAP (caller 层) | 外设 BAR 区,读可能触发 bus error |
5.4 pte_offset_map 为什么”够稳”
pte_offset_map 在 ARM64 4-level 下等价于 PMD 页里的线性映射,返回的 ptep 就是内核 linear map 里一个稳定的虚拟地址;pte_unmap 在 ARM64 上是 NO-OP,但我们保留调用是为了跨架构 / 将来 5-level / kmap 实现可能改。
结论:在持 mmap_read_lock 的窗口内,ptep 读出来的 pte_t 值是可信的;一旦松锁,PTE 就可能被 mmu_notifier / THP split / migration 改掉,因此每次扫描必须在锁内完成 page 锁(get_page)。kern_mem.h:531-532:
get_page(pr.page);
if (pr.ptep) pte_unmap(pr.ptep);顺序很重要:先 get_page(增引用阻止 free),再 pte_unmap(在其他架构上是真正的 kunmap)。
5.5 AF bit / S1PIE 影响
ARM64 访问位(AF, Access Flag)和阶段-1 间接权限编码(S1PIE,SM8750 启用)不影响 pte_present 的判断 —— 只要 PTE 的 valid 位(bit 0)为 1,我们就能读。
AF bit 的意义:CPU 第一次访问时若未置,硬件会 fault 由 kernel 置位。对我们 scan 的 side-effect 是:一次全内存扫会把所有 AF 都置成 1,这个状态对进程本身无副作用,但 /proc/pid/pagemap 里会看到一大片 “accessed” 位 —— 反作弊没人扫这个,保密级别够。
S1PIE 的重映射只改变 aarch64 硬件 MMU 如何解释 AP/PXN/UXN 组合,对 kernel 侧 pte_val() 的位表示不变。扫描逻辑无需感知。
5.6 Huge page 处理的 limitation
if (pud_sect(...)) { res.size = PUD_SIZE; ... return; }
if (pmd_sect(...)) { res.size = PMD_SIZE; ... return; }返回的 res.size 是 huge page 的实际大小。调用方(mem_rw)在 write path 里根据 res.size 重算 pgoff:
if (pr.size > PAGE_SIZE) {
pgoff = va & (pr.size - 1) & ~PAGE_MASK;
}但 kmap_local_page(pr.page) 只映射 4KB,对应的是 huge page 的 head page。读写 huge page 内部跨 4KB 边界的数据时会取错 —— 这是一个已知 limitation:2MB THP 上访问跨 4KB 边界的值不可靠。UE4 游戏 heap 多为 non-huge 匿名映射,实测未触发。
5.7 整页读 + 刷 icache
kern_mem.h:259-272 的 write 路径:
if (write) {
if (copy_from_user(kaddr + pgoff, (void __user *)(req->buf + done), chunk))
ret = -EFAULT;
else if (vma->vm_flags & VM_EXEC) {
flush_icache_range((unsigned long)(kaddr + pgoff),
(unsigned long)(kaddr + pgoff + chunk));
}
}写可执行页必须刷 icache,否则目标进程继续执行老指令 —— 历次踩坑的经典项。
5.8 PTE 断点集成
kern_mem.h:228-237 里有个可选的 hook:
#ifdef PTEBP_H
/* PTE trapped? Look through to original physical page */
pr.page = ptebp_find_trapped_page(mm, va);
if (pr.page) {
pr.size = PAGE_SIZE;
pr.ptep = NULL;
}
#endif当 PTE 断点把页标成 “not present” 陷入 fault handler 时,正常 walk 会失败。这个 fallback 让 scan / read 能透过断点拿到原始物理页,保证断点存在时内存扫描依然工作。详见 内核 PTE 断点。
6. 协议 (shadow_ce.h 与 usr_server.c)
6.1 TCP 层包格式
每条 CE 请求的前 1 字节是 cmd opcode,后面是固定 layout 的 packed struct(每个 cmd 独立定义)。响应也是固定 layout —— 没有全局 header、没有 length 前缀、没有版本号。Server 靠 recvall(sock, &cmd, 1) 一字节读开头,然后 switch (cmd) 进入对应 handler。
优点:简单、和 CE 原协议兼容(CE 7.x 可以直接连)。
缺点:协议里一个 bug 错位整个 connection 只能重连。
6.2 CMD opcode 清单
从 usr_server.c:27-60 全量提取:
| CMD | 值 | 类别 | 用途 |
|---|---|---|---|
CMD_GETVERSION | 0 | 握手 | 返回 CE 版本号 + "CHEATENGINE Network 2.3" |
CMD_CLOSECONNECTION | 1 | 控制 | 关闭连接 |
CMD_TERMINATESERVER | 2 | 控制 | 关闭 server 线程 |
CMD_OPENPROCESS | 3 | 进程 | 设置 opened_pid |
CMD_CREATETOOLHELP32SNAPSHOT | 4 | 进程 | 建进程列表快照 |
CMD_PROCESS32FIRST/NEXT | 5/6 | 进程 | 迭代进程快照 |
CMD_CLOSEHANDLE | 7 | 控制 | 关闭伪 handle |
CMD_VIRTUALQUERYEX | 8 | VMA | 查单地址的 VMA |
CMD_READPROCESSMEMORY | 9 | 内存 | 单发读(最大 16MB) |
CMD_WRITEPROCESSMEMORY | 10 | 内存 | 单发写 |
CMD_GETARCHITECTURE | 12 | 握手 | 返回 3 (arm64) |
CMD_MODULE32FIRST/NEXT | 13/14 | 模块 | 传统 per-module 迭代 |
CMD_VIRTUALQUERYEXFULL | 31 | VMA | 全量 VMA dump |
CMD_GETABI | 33 | 握手 | 返回 ABI 标识 |
CMD_SCAN | 0xC8 | 扫描 | First scan |
CMD_RESCAN | 0xC9 | 扫描 | Next scan |
CMD_MODULE_LIST_BULK | 0xCA | 模块 | 定制:一次拿全部模块 |
CMD_READ_BATCH | 0xCB | 内存 | 定制:N 个小块一次读(value 刷新用) |
CMD_HWBP_SET/CLEAR/CLEAR_ALL/POLL | 0xCC-0xCF | HWBP | 见 用户态硬件断点 |
CMD_PTEBP_* | 0xD0-0xD4 | 断点 | 见 内核 PTE 断点 |
CMD_PTRSCAN/DUMP/CHAIN_RESCAN | 0xD6-0xD8 | 指针 | 见 指针扫描 |
CMD_EHWBP_* | 0xE0-0xE5 | 断点 | 见 极致优化硬件断点 |
内核 ioctl 映射(shadow_ce.h):
| ioctl | 值 | 结构 |
|---|---|---|
SHADOW_CE_READ | _IOWR('C', 1, ce_rw_req) | {pid, addr, size, buf} |
SHADOW_CE_WRITE | _IOWR('C', 2, ce_rw_req) | 同上 |
SHADOW_CE_LISTPROC | _IOWR('C', 3, ce_proc_list) | {count, buf} |
SHADOW_CE_LISTVMA | _IOWR('C', 4, ce_vma_list) | {pid, count, buf} |
SHADOW_CE_SCAN | _IOWR('C', 5, ce_scan_req) | 详见 shadow_ce.h:62-75 |
SHADOW_CE_RESCAN | _IOWR('C', 6, ce_rescan_req) | 详见 shadow_ce.h:92-108 |
6.3 TCP socket 细节
- 默认端口 52736(CE 原生默认),ce_server 启动时可用
-p覆盖(usr_server.c:1214-1216)。实际部署里我们用 16900(ADB forward 固定端口)。 SO_REUSEADDR开启(usr_server.c:1232)—— 方便频繁重启 server 不等 TIME_WAIT。TCP_NODELAY开启(usr_server.c:1267)—— 小包响应无 Nagle 延迟。- 每个客户端连接启一个
pthread(pthread_detach,usr_server.c:1276-1277)。Server 里g_devfd全局 ioctl fd,线程间共享 —— 所以同时间只能有一个大 scan 在跑。 - 单连接的命令必须严格串行(没有 request id / stream),客户端
ce_client.py:11用threading.Lock保证。
6.4 Client send/recv 封装
ce_client.py:36-59 —— 两个简单的 loop 直到收齐 N 字节:
def _send(self, data):
try: self.sock.sendall(data)
except (BrokenPipeError, ConnectionResetError, OSError):
self.connected = False; raise
def _recv(self, n):
buf = b""
while len(buf) < n:
chunk = self.sock.recv(n - len(buf))
if not chunk:
self.connected = False
raise ConnectionError("closed")
buf += chunk
return buf每个命令用 self._lock(threading.Lock)串行化 —— 客户端是多线程的(scan / refresh / UI 都可能发),没这把锁 TCP 流会交错错位。曾经写 write_memory 漏了锁,Memory View 全屏 0x00 20 秒。
6.5 Server-side scan 的参数落地
usr_server.c:651-706 的完整 CMD_SCAN handler:
- 收 56 字节 packed struct。
- 校正
max_results(0 → 100000,> 10M → 10M)。 malloc(max_results * 8)用户态暂存。- 构造
ce_scan_req,把result_buf指向这块 malloc。 ioctl(g_devfd, SHADOW_CE_SCAN, &kreq)。sendall(count)→sendall(addrs * 8)。
内核 mem_scan 里的 copy_to_user 目的地就是 server malloc 的这块 —— 一次扫回来,不分页,因为 server 在本机 127.0.0.1,内存不紧张。
6.6 Device fd 动态发现与热重连
ce_server 启动时调 find_ce_dev(usr_server.c:1176-1196)扫 /dev/cx??????(8 字符),打开第一个;失败 fallback /dev/shadow_ce(legacy 路径)。
运行中如果 ko 被 rmmod → 重新 insmod,ioctl 返回 ENODEV/EBADF,ce_read_mem / ce_write_mem(usr_server.c:359-365, 387-393)会自动调 reopen_devfd 再重试一次。所以 client 端不感知 ko 重启,只要设备名前缀还是 cx 即可。
7. mem_cache 机制
内存扫描本身不用 mem_cache —— scanner 直接同步读 ioctl。mem_cache.py 服务的是 Hex View / Disasm View / value refresh:
- Hex View 滚动浏览时,每个滚动 tick 如果还要发 TCP 就会卡 —— cache 先把已读的 4KB 页存下来,再次命中零 RTT。
- First scan 返回几十万地址、UI 只显示可见的 ~50 行;background refresh 线程每 300ms 批读一次(
_refresh_result_values),读回来的数据不进 mem_cache,只填ResultsModel._live_values(main_window.py:1230-1233)。
7.1 Cache 结构
mem_cache.py:6-19:
class MemoryCache:
PAGE_SIZE = 4096
MAX_PAGES = 128 # LRU cap → 512 KB
FADE_MS = 1000 # 变化高亮淡出时长
self._pages = OrderedDict() # pb → 4KB bytes
self._change_times = {} # abs addr → timestampLRU(move_to_end + popitem(last=False),mem_cache.py:59, 105)—— 128 页 = 512KB 工作集,覆盖 Hex View 几屏滚动。
7.2 非阻塞读 + 背景 fetch
def read(self, addr, size, blocking=False):
# 找缺页,加入 missing[]
if missing:
if blocking:
self._bulk_fetch(missing) # 阻塞等
else:
self._schedule_fetch(missing) # 丢到 queue,立刻返回零
# 已缓存的页正常返回,缺失页返回 00blocking=False 时缺失页返回 b"\x00" 填充 —— UI 渲染立刻有东西显示,下一帧 background 填充回来刷新。
7.3 持久化 fetch 线程
def _ensure_fetch_thread(self):
if not hasattr(self, '_fetch_q'):
self._fetch_q = queue.Queue(maxsize=4)
threading.Thread(target=self._fetch_loop, daemon=True).start()
def _fetch_loop(self):
while True:
pages = self._fetch_q.get()
self._bulk_fetch(pages)一个持久化的 fetch 线程,不是每次 read() 都 Thread() —— 早期实现每 read 起一个线程,滚动 Hex View 时每秒能创 60+ 个,GIL 抖动严重。
7.4 连续页合并
_merge_runs(mem_cache.py:179-194):把缺失的离散页号按 4KB 连续性合并成 (start, count) runs —— 一次 ioctl 读 runs[i].count * 4096 字节,省 TCP 往返。
7.5 Change tracking(用于淡出高亮)
refresh(mem_cache.py:63-109)—— 对 ranges 内的页重新拉一次,和 cache 里的旧 bytes 逐字节 diff,变了就记 change_times[abs_addr] = now。后续 get_change_alphas(mem_cache.py:111-125)按 1000ms 线性淡出算 alpha,Hex View / disasm 据此给变化的字节做红→透的动画。
这条路径只在 refresh-on-timer 里用,scan 不触发。详见 反汇编 / Hexview。
7.6 Invalidate
invalidate_page 让 Hex View 在写内存后立刻失效缓存(下次读必重新拉)—— 跨视图数据一致的最后一道保险。
8. 性能关键点
8.1 批量 pack / unpack(Python 侧)
ce_client.py:192一次拼好所有 addrs 再 send:1M 个地址大约 16ms 拼包(CPython),比逐个 send 快 50×(每个 send 有 syscall overhead)。self._send(b"".join(struct.pack("<Q", a) for a in addrs))- Scan 响应
self._recv(count * 8)一次性收 再 for-loop unpack,不是每 8 字节一次 recv。
8.2 READ_BATCH 合并 value 刷新
_refresh_result_values(main_window.py:1227-1285):
- 取屏幕可见的 ~30 行(
rowAt(0)到rowAt(height))。 - 一次
read_memory_batch(h, [(addr1, sz), (addr2, sz), ...])发 30 个读到 server。 - Server 端(
usr_server.c:819-842)逐个 ioctl,拼完一次 send 回来。
单个 READ_BATCH RTT ≈ 2ms(含内核 30 次 walk),比 30 个独立 CMD_READPROCESSMEMORY 快 20×。
8.3 Live value 批量 dataChanged
ResultsModel.batch_update(main_window.py:126-138):
def batch_update(self, updates):
self._live_values.update(valid)
rows = sorted(valid)
self.dataChanged.emit(self.index(rows[0], 0),
self.index(rows[-1], 3))一个 dataChanged 信号覆盖 30 行,而不是每行一个 —— PyQt6 下 30 个独立 dataChanged 会 invalidate 30 次布局,肉眼可见卡顿。
8.4 结果数量上限与显示截断
- 协议层:
max_results上限 10M(kern_mem.h:471-472,shadow_ce.h:62-75)。 - 客户端 UI:
ResultsModel.MAX_DISPLAY默认0(unlimited),用户可在 Settings 里改(main_window.py:806-808, 830-832)。超过上限时lbl_found显示"found N (显示 CAP)"(main_window.py:1214-1215)。
UE4 游戏 first scan 常出 500K-2M 个假阳,MAX_DISPLAY 通常设 10000;scan 结果集不截断(Scanner 里仍然保留全集),只裁显示。next-scan 还是用全集过滤。
8.5 内核侧 vmalloc
mem_scan 的 results = vmalloc(max_results * 8) —— 10M × 8 = 80MB。kmalloc 80MB 一定失败,vmalloc 走 per-page 分配 + vmap,10MB/s 级别的分配速度,可接受。
8.6 cond_resched() 的必要性
kern_mem.h:567 每块(1024 页)后调一次。ARM64 内核默认 CONFIG_PREEMPT=y(OnePlus 上实测),但 mmap_read_lock 里是 rwsem,持锁时虽然可抢占,但其他线程想拿 mmap_write_lock(例如 malloc 触发 brk)会阻塞。分块 + cond_resched 让写锁者能切入。
8.7 静态缓存 vs 动态值双层设计
ResultsModel._static_cache(main_window.py:78-90)—— per-row 的 (prev_str, first_str, val_str) 三元组懒缓存,只在第一次渲染时计算,之后读 data() 零开销。
_live_values(main_window.py:40)—— 异步刷新线程填进来的最新 Value 字符串,覆盖 _static_cache 的 val_str 显示。当 live != static 时用红色字染(main_window.py:110-113)—— 这就是 “value changed” 提示。
9. 用户侧扫描工作流(speed run)
扫完之后右键任一行可直接派发到后续工作流:
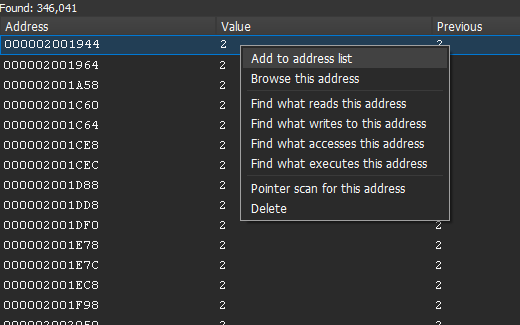
Add to address list / Browse this address / Find what reads|writes|accesses|executes this address / Pointer scan for this address / Delete —— 从扫描结果到地址表、到 Memory View、到 用户态硬件断点 / PTE 断点、到 指针扫描,一步跳。
以 FPS2 查找弹药值为例:
Step 1 —— First scan
- UI 点进程列表,选
com.ShuiSha.FPS2,点 Select。(打开 handle) - Value Type 选
4 Bytes。 - Scan Type 选
Exact Value。 - 开火打出已知弹药数(比如 30),Value 填
30,勾 Writable(过滤掉 r-x 只读区)。 - Start/Stop 保持默认
0→7fffffffffff。 - 点 First Scan —— UE4 游戏里 Exact Value=30 通常 200K-500K 命中。
Step 2 —— Next scan
- 开枪让弹药掉到 29。
- Scan Type 改
Decreased(或者精确Exact Value 29)。 - 点 Next Scan —— 通常缩到 100-1000 地址。
- 再开一枪 →
Decreased→ ≤ 10 个候选。 - 换弹夹回到 30 →
Exact Value 30→ 基本定位到。
Step 3 —— 锁值 / 写值
拖到 Address List 里(或右键 Add to Address List)。勾 Frozen 让 value 持续被覆盖 —— 锁值通过 CMD_WRITEPROCESSMEMORY 每 300ms 写一次(AddrEntry.frozen,scanner.py:32-33)。
Step 4 —— Hex / Disasm 跳转
Address List 里右键 → Open in Hex View / Disasm View,查看周边数据结构或指令。Hex View 通过 mem_cache.read(blocking=False) 先渲染 0,300ms 后背景填真值(§ 7.2)。
Step 5 —— 做指针链
有了动态地址但想跨重启稳定 → 右键 Pointer Scan(详见 指针扫描)。
实战技巧
- 先用 Exact Value 缩一轮再转 Changed/Unchanged。直接从 Unknown + Changed 开始会出几百万假阳。
- 勾 Writable:UE4 heap + stack 都在 writable 区,能砍 80% 扫描时间。
align参数:默认跟val_size。4 字节值设align=1可以发现未对齐字段,但时间 × 4。用来找 packed struct 内 offset 用。- Start/Stop 缩范围:如果已经通过
maps看到目标 heap VMA,把范围限定到那段,first scan 从 300K → 3K 量级。 - 不要扫整个 47-bit 地址空间的 R-X 页:executable 内存是代码,基本不含可变状态。
- float 用 Between 近似:因为
SCAN_EXACT对 float 是 bit-exact 比较,给 99.5-100.5 能容下浮点漂移。 - Next scan Decreased 是神器:任何数值随时间减(HP、ammo、cooldown)都能几轮定位。
- TerSafe 检测:严禁
/proc/pid/mem,整条链路已经不碰它;扫描本身对 target 进程无可观测副作用(只读页表、get_page增引用,无 signal、无 singlestep)。
Appendix — 关键文件清单
| 文件 | 行数 | 主要职责 |
|---|---|---|
shadow_ce/client/scanner.py | 86 | VALUE_TYPES、ScanResult、AddrEntry、Scanner class |
shadow_ce/client/mem_cache.py | 194 | 页缓存、fetch 线程、change tracking |
shadow_ce/client/ce_client.py | 580 | TCP 协议封装(scan / rescan / read_memory_batch / 等) |
shadow_ce/client/main_window.py:980-1290 | ~300 | Scan UI 逻辑、results model、value refresh |
shadow_ce/server/shadow_ce.h | 293 | ioctl + struct 定义(ce_scan_req / ce_rescan_req / …) |
shadow_ce/server/kern_mem.h | 714 | mem_walk_pte / mem_rw / mem_scan / mem_rescan |
shadow_ce/server/kern_shadow_ce.c | 346 | ko 主入口、ioctl dispatcher、misc device 注册 |
shadow_ce/server/usr_server.c | 1284 | TCP server、CE 协议 handler、ioctl 调用 |
shadow_ce/server/Makefile | 17 | 内核模块构建(ARCH=arm64 LLVM=1 CC=clang) |